Faster, cheaper, and better: A story of breaking a monolith
Intro
Disclaimer: Fair is Sep Dehpour’s employer at the time of writing this article.
If you don’t know about Fair, we are a vehicle subscription app. So when it came to naming the monolith that was dealing with vehicles, it was a no-brainer to call it vehicle-service. As the team grew, soon the on-boarding, testing, and development became slow and painful. We needed to release search updates independently and changes were frequent. But we could only move as fast as the slowest gear, the monolith itself.
TL;DR:
On May 21st 2019, we broke search service out of vehicle-service. It was faster, cheaper, and better!

Faster
The same API in the new service is around 4x times faster. It is so much faster that it caused the anomaly detector to trigger alerts!
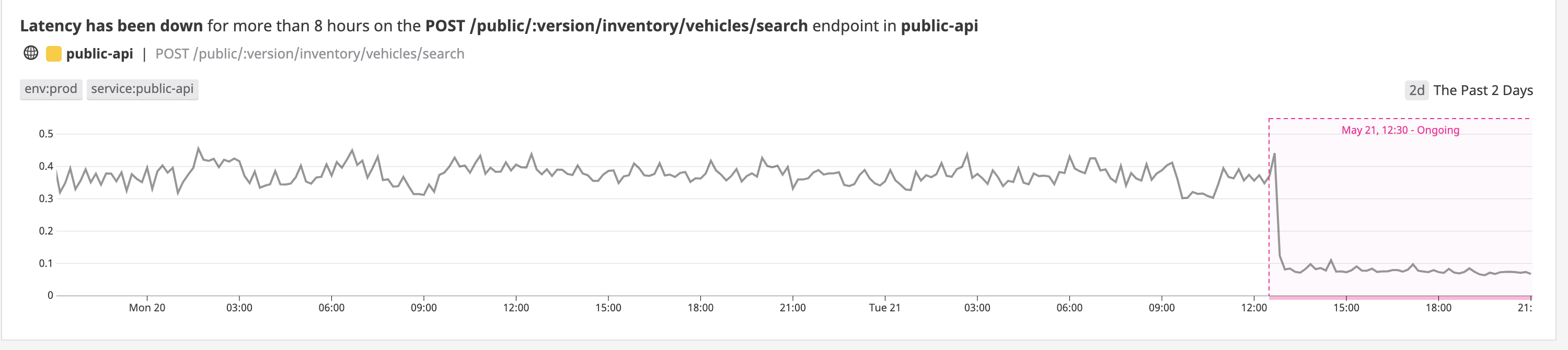
Not to mention, it is faster to setup, develop, and run tests: tests run 10x faster!
Cheaper
It is also cheaper to run. We estimate that it is going to save us hundreds of thousands of dollars3 annually in infrastructure costs!
Better
Last but not the least, it resulted in better code quality, monitoring, and bug fixing. All issues are now immediately noticed and resolved.
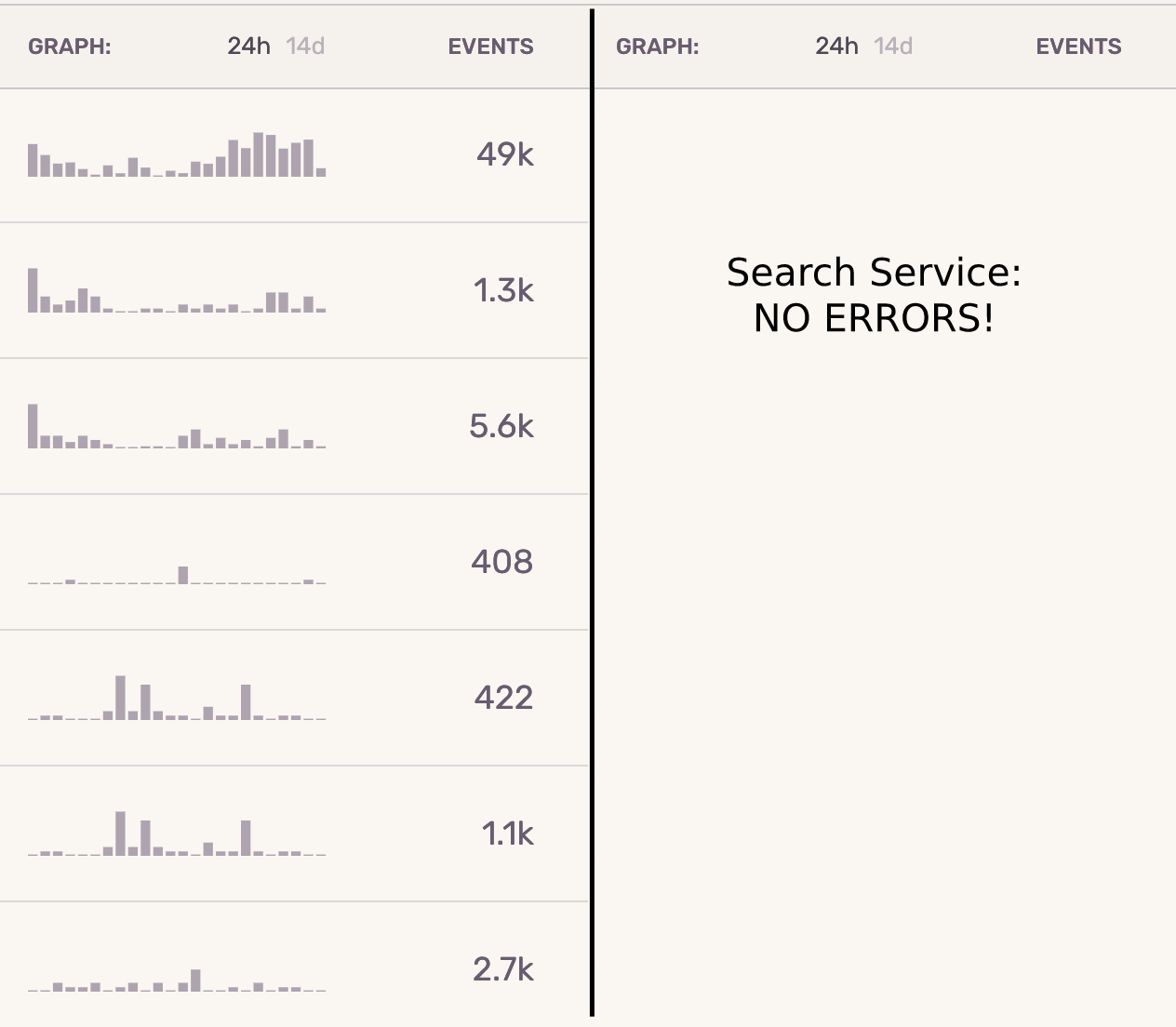
Below is an example of errors in the span of 24 hours in vehicle-service on the left vs. search-service on the right. Search errors on the monolith could easily get lost in the sea of other errors.
Monolithic vs. Micro-Services Architecture
There are trade-offs between using a monolithic 1 vs. a micro-services architecture.
The main benefits of a monolithic architecture are:
- Shared source code
- Shared responsibility
- Simple architecture
- Simple to deploy
The main benefits of a micro-services architecture are:
- Team ownership of source code (assuming not monolithic repo)
- Independent releases
- Easier for on-boarding new engineers
- Scale micro-services independently
Some companies do really well with monoliths. Some don’t. Almost everybody starts with the monolithic architecture though. At the early stages of a project, the team is small and the problem domains may not be clear yet. So it is usually over-engineering to start with micro-services. But at some point the monolith becomes too big and slow to change, especially if the culture of the company rewards doing shortcuts that bring immediate value to the business. The code quality starts to degrade at the expense of long-term sustainability. Technical debt sky rockets. That’s when engineers start complaining about the monolith and propose projects to “break the monolith”. However, there is a non-trivial amount of work to separate a monolith into micro-services. It is usually underestimated.
What makes a good break
After going through a number of monolith breakup projects at various places, I have come to the conclusion that you need to:
-
Have the right reasons to break the monolith. Constantly evaluate the cost of the separation against “fixing” the monolith.
We decided to move into micro-services architecture at Fair in order to give each team the “ownership” of the service they were working on, reduce blockers, move faster, and release independently.
-
Decouple the right functionalities: what changes frequently and needs to move faster.
We started breaking out the 2 major user facing functionalities: search and auto-complete. The rest of this article focuses on search. You can read about auto-complete here.
-
Be committed to decoupling. Don’t share a database between services even if it means some duplicate data.
-
While it is generally a bad idea to increase the scope of a project that is already non-trivial, don’t just move the problems from one code base to another. The new service needs to have an immediate tangible impact both for the end user and the business in order to pave the way for other breakouts from the monolith.
Different ways to break
There are generally 4 ways to break:
- Rewrite a new service from scratch
- Clone the original monolith and trim the code.
- Grow the new service inside the monolith and then separate.
- Copy paste all the relevant pieces of code + tests and refactor.
As an engineer, it is always intriguing to start a new service from scratch. We did actually spend a few weeks down this road before coming to realization that it was impractical. As Joel Spolsky puts it, starting from scratch is the single worst strategic mistake that any software company can make.
The monolith was too big. Cloning and trimming it would have taken too long. What we ended up doing was option 4: Copy pasting all the relevant pieces of code and refactor.
Hint: make sure you have good test coverage in the monolith before you start. Once you copy the tests to the new service, resist all urges to modify the tests. You can either refactor the code or the tests at a time but not both!
Part A: Re-architecture
Monolith Architecture
Here is a simplified diagram of the parts of the monolith related to search:

Notice how RDS and Elasticsearch were intertwined for all apis. Any performance issues of the APIs or the Relational Database (RDS) would propagate to search. If the RDS timed out, if the IDs were running out, or if our own inventory processing workers had scaled up beyond the capacity of the RDS, the end user would have experienced a slow search.
Search Service Architecture
Since the RDS was one of the big obstacles in scaling search, we removed it in the search service. The Elasticsearch data needed to have everything that search would have utilized. That effectively made Elasticsearch the source of truth.

Monolith to publish, Search to subscribe
In order to make sure the Elasticsearch in search had all the data needed while giving us the flexibility to iterate on the new service, turn the new service off, turn it back on, and still catch up with the changes, we went with the Pubsub pattern. That way the monolith and search service did not even need to know about each other and we could achieve true decoupling.
We used the AWS SQS (unordered queue) but even better if you use something like Kafka.

Part B: Catching up with a moving target
The monolith is a moving target. New features are constantly being developed and we could not slow down the development just so that the search service could catch up.
One could say, just develop the micro service as fast as you can to catch-up. That’s easy in theory. Maybe you are lucky and can have “code freezes”. We don’t have that luxury.
The following helped with catching search up to the monolith functionalities:
Traffic Mirroring/Shadowing
We had all search traffic mirrored to hit both the monolith and the micro-service in all environments (even prod). That way we could develop, deploy, monitor, and measure search service’s performance and functionalities. Most importantly, doing so would build the confidence that the micro-service works as well if not better than the monolith.
The prerequisites to traffic mirroring are:
- Making sure that the data storages are truly separate and there is no chance of impacting the critical path of the monolith.
- Keeping the APIs consistent between the monolith and the micro-service. From the perspective of the client of the API, only the service name and nothing else should change.
- Have a way to mirror the traffic.
Traffic Mirroring via Service Mesh
A great way to do traffic mirroring is to use a service mesh layer. For example, mirroring in Istio.
However, at the time of separating the search service, we did not have a service mesh layer in our Kubernetes cluster. Therefore mirroring via service mesh was not a feasible option.
Traffic Mirroring via UDP + Queue
Since we did not have the option of using the service mesh at the time, we resolved to creating a server to handle traffic mirroring. Once a request was received by the monolith, the request plus the monolith’s response was sent to this simple server via UDP. Then this information was put on a queue. A queue worker would pop the request and make the same request to the micro-service and compare the results between the monolith and the micro-service:

Why UDP?
- Acknowledge packet (ACK) does not exist in UDP. We did not need acknowledgments when mirroring.
- We did not care if some UDP packets were dropped.
- Most importantly, under no circumstances should the performance of the “receiver” (simple mirroing service)have affected the monolith.
UDP and network congestion
Using UDP had its own slight risk of UDP taking over the network traffic if we ran into network congestion. We decided that the risk was minimal and moved forward with using UDP. (UDP lacks the TCP congestion control.)
New features developed in the micro-service before the monolith
It also helped to develop new features and business requirements first in the micro-service and then in the monolith. This way both the monolith and the micro-service needed to catch up with each other instead of one always chasing the other.
Part C: Refactor and Optimize before switching all the traffic
In our case we focused on 2 areas to deliver value:
A. Elasticsearch Optimizations
The main areas of focus for the refactor were:
- Flatten the data
- Keep superfluous information in binary form
- Don’t leave doc_values and index values to defaults
- Index only if new or changed
- Remove unnecessary abstractions
- Optimize the number of shards, replicas and indices
1. Flatten the data
The lack of limitation is the enemy of data structure2
Arguably one of the strengths and at the same time a weakness of Elasticsearch is that you don’t have to design a schema. You can literally shove in anything in json format and let Elasticsearch handle it. That’s great for something like holding the logs in the ELK stack. But when it comes to using Elasticsearch in an application, it is a different story. That lack of limitation gives you a lot of freedom in the short-term, but it will bite you when you need to scale your application.
Thanks to this freedom, all sorts of data was shoved into Elasticsearch in our monolith, whether it was used for querying or not. Worst of all the data was deeply nested.
Elasticsearch under the hood is using Lucene to index data. Lucene indexes are flat. So when you have a nested data structure, it creates hidden separate indexes per level of the nested data. If you are doing a nested query, it will quickly get ugly and slow.
Flattening the data structure arguably contributed the most to reducing our APIs latency by 4x.
In order to flatten the data, we used “name spacing” to move the nested fields to the root of the document. For example:
{
"foo": {
"bar": ""
}
}became: {"foo__bar": ""}
We went from a nested data-structure with a max depth of 5 to a flat data-structure with a depth of one.
This is what the nested data-structure in the monolith’s Elasticsearch looked like:

(A screen-shot of the Elasticsearch mapping rotated 90 degrees to fit this page horizontally.)
And once it was flattened:

Do you see how simpler it looks? And there are less fields. Which brings us to point 2:
2. Keep superfluous information in binary form
Remove any fields that don’t need to be searchable. Put them all into one binary blob field.
For example, in our case the “single vehicle detail page” had way more fields such as image links and other information that did not need to be searchable or visible in the “list view”. By putting all those fields into a binary blob, we could efficiently store and retrieve them just for the “detail view”.
3. Don’t leave doc_values and index values to defaults
Use the correct Elasticsearch attributes for the field. Ask yourself the following questions:
-
Do I ever need to query this field?
If yes, then keep it
index=true. Otherwiseindex=false. By having it asindex=false, it won’t be added to Lucene’s inverted index. -
Do I ever need to sort by this field or run aggregations on it, or access it through a script?
If yes, make the
doc_value=true. Otherwisedoc_value=false. This one specifically will save you disk space by setting it to false.
4. Index only if new or changed.
Avoid indexing something that is already indexed. If nothing has changed, don’t index it again. This is where we used DeepDiff’s DeepHash to generate a Murmur3 hash of the Elasticsearch payloads. Before inserting any new document, we could compare the hash of the old vs. new document along with the timestamp of the document to determine if anything needed to be indexed. You might wonder why “timestamp” is needed in addition to the hash. The reason is that we use the un-ordered AWS SQS queue. So messages will not be received in the order they were sent. You only want the latest “state”.
5. Remove unnecessary abstractions
We used the Elasticsearch-DSL library to give us a nice object oriented interface into Elasticsearch. While this library is written with good intentions, if you are doing anything serious with Elasticsearch, I highly discourage you from using this library. Both at my current job at Fair and at my previous job at Chownow, I got rid of this library and switched to Elasticsearch-Py which is a lower level library. Both libraries are brought to you by Elastic, the company behind Elasticsearch. But the unnecessary abstractions that the higher level library creates to shove things into an object oriented interface comes at a high cost: Bugs are prevalent, many Elasticsearch features are unsupported, and you need to learn a new object oriented query language when dealing with Elasticsearch.
Switching to the lower level library also meant our code became more “functional” which made testing way easier.
6. Optimize the number of shards, replicas and indices
Depending on your use case, you may want to optimize these settings for reads, writes, memory, cpu usage or a combination of them. In Elasticsearch, pay attention to the number of shards, replicas, and indices.
Aiming for faster reads in the micro-service, we reduced the number of shards per index to one, increased the number of replicas and more importantly reduced the number of indices by 1000x relative to the monolith.
B. Unittest optimizations
One of the bottlenecks in the monolith dev work was how slow tests were running. While you don’t want to refactor the tests themselves during the breaking, you may find ways to increase the tests’ speed. In our case, we were loading fixtures into Elasticsearch and RDS more often than necessary. As an optimization, when tests were not modifying the state and could use the same data in Elasticsearch, we grouped them together and loaded the data once. That alone made the tests run 10x faster.
Part D: Final Architecture: KISS
And finally, this is our simplified high level architecture that is relevant to this article. As they say, Keep It Simple Stupid!

Part E: Stay Committed and finish the breakout!
Separating a monolith into micro-services is non-trivial. No matter what path you take, expect to discover issues and dependencies that will increase the scope of the project. Throughout the breakout, there will be questions about whether to continue with the break or focus resources elsewhere to bring immediate value to the company. Don’t forget: It’s a Marathon not a sprint. Be prepared. Start by breaking smaller user facing functionalities and make them clear winners on all fronts first. That paves the way to break more complicated components later on.
Good luck!
Sep Dehpour
To discuss this article please visit Hacker News
Footnotes
-
1: Monolith Service
We are talking about monolith service not monolith code as they do in Google
-
2: The lack of limitation is the enemy of data structure
That’s originally a quote by Orson Welles that I took the liberty to modify. https://www.brainyquote.com/quotes/orson_welles_109697
-
3: save us hundreds of thousands of dollars
A lot of the cost savings were because we could decrease the size of our elasticsearch cluster. This was mostly due to the flattening of the elasticsearch document schema, which improved performance dramatically but also allowed us to run significantly fewer ES nodes.